파이프(Pipes)
두 프로세스가 통신할 수 있도록 하는 전송 경로 역할을 함
주요 문제
통신 방식: 단방향인가 양방향인가?
양방향 통신일 경우: 반이중(Half-Duplex)인가 전이중(Full-Duplex)인가?
프로세스 관계: 통신하는 프로세스 간에 부모-자식 관계가 반드시 존재해야 하는가?
네트워크 사용 가능 여부: 파이프를 네트워크를 통해 사용할 수 있는가?
일반적인 파이프(Ordinary Pipes)
일반적인 파이프는 생산자-소비자(Producer-Consumer) 방식으로 통신을 수행함
데이터를 생산하는 프로세스(Producer)가 데이터를 쓰고, 소비하는 프로세스(Consumer)가 데이터를 읽는 구조임.
생산자(Producer)는 파이프의 쓰기 끝(write-end)에 데이터를 기록함
생산자는 write() 시스템 호출을 사용하여 데이터를 파이프에 입력함.
소비자(Consumer)는 파이프의 읽기 끝(read-end)에서 데이터를 읽음
소비자는 read() 시스템 호출을 사용하여 파이프에서 데이터를 가져옴.
따라서, 일반적인 파이프는 단방향(Unidirectional) 통신만 가능함
데이터가 한 방향으로만 흐르므로, 양방향 통신을 위해서는 두 개의 파이프가 필요함.
부모-자식(Parent-Child) 프로세스 간에만 사용 가능함
익명(anonymous) 파이프는 fork() 시스템 호출을 통해 생성된 부모와 자식 프로세스 간에서만 동작함.

일반적인 파이프(Ordinary Pipe)
부모 프로세스가 자식 프로세스에게 "Greetings"라는 메시지를 보내려고 합니다.
파이프(pipe)를 생성하면 두 개의 파일 디스크립터(file descriptor, fd)가 반환됩니다.
하나는 쓰기(write)용
하나는 읽기(read)용
부모 프로세스는 쓰기 파일 디스크립터를 사용하여 데이터를 씁니다.
자식 프로세스는 읽기 파일 디스크립터를 사용하여 데이터를 읽습니다.
주요 개념:
pipe() 시스템 호출
pipe()를 호출하면 두 개의 파일 디스크립터(fd)가 생성됩니다.
하나는 **쓰기(w)**용, 하나는 **읽기(r)**용입니다.
fork()를 통한 프로세스 생성
fork()가 호출되면 부모 프로세스와 자식 프로세스가 생성됩니다.
두 프로세스 모두 동일한 파일 디스크립터를 공유합니다.
통신 방식
부모 프로세스는 **쓰기(write)**를 담당합니다.
자식 프로세스는 **읽기(read)**를 담당합니다.
즉, 부모가 데이터를 파이프를 통해 쓰면, 자식이 이를 읽습니다.
정리
pipe(): 두 개의 fd(파일 디스크립터) 생성 (w: write, r: read)
fork(): 부모-자식 프로세스를 생성하여 fd를 공유
write(): 부모가 파이프에 데이터를 씀
read(): 자식이 파이프에서 데이터를 읽음
Named Pipe(이름 있는 파이프)
일반적인 파이프(Ordinary Pipe)는 프로세스가 종료되면 사라집니다.
→ 일반적인 파이프는 부모-자식 프로세스 간의 일시적인 통신을 위해 생성되며, 프로세스가 종료되면 자동으로 소멸됩니다.
Named Pipe(이름 있는 파이프)는 일반적인 파이프보다 더 강력한 기능을 제공합니다.
→ Named Pipe는 파일 시스템 내에서 특정 이름을 가지며, 여러 프로세스 간 지속적인 데이터 공유가 가능합니다.
양방향 통신(Bidirectional Communication)이 가능합니다.
→ 일반적인 파이프는 단방향(읽기 또는 쓰기)으로만 동작하지만, Named Pipe는 한쪽에서 데이터를 보내면서 동시에 받을 수도 있습니다.
부모-자식 프로세스 관계가 필요 없습니다.
→ Ordinary Pipe는 fork()를 통해 생성된 부모-자식 프로세스 간의 통신을 지원하지만, Named Pipe는 전혀 관계없는 프로세스 간에도 사용할 수 있습니다.
여러 개의 프로세스가 사용할 수 있습니다. (예: 여러 개의 프로세스가 데이터를 쓸 수 있음)
→ 여러 개의 독립적인 프로세스가 동일한 Named Pipe를 열어 데이터를 동시에 주고받을 수 있어, 보다 유연한 IPC가 가능합니다.
프로세스가 종료된 후에도 존재합니다.
→ 일반적인 파이프는 프로세스가 끝나면 사라지지만, Named Pipe는 시스템에서 삭제되지 않는 한 계속 유지됩니다.
UNIX와 Windows 시스템 모두에서 제공됩니다.
UNIX에서의 Named Pipe
FIFO(First In, First Out)라고 불립니다.
→ 데이터를 저장하는 방식이 큐(Queue)처럼 먼저 들어온 데이터가 먼저 나갑니다.
mkfifo()로 생성하면 파일처럼 동작합니다.
→ 파이프를 만들면 일반 파일처럼 open(), read(), write(), close() 함수를 사용할 수 있습니다.
파일 시스템에서 삭제되지 않는 한 계속 존재합니다.
→ 일반적인 파이프와 달리, 프로세스가 종료되더라도 파일 형태로 남아 있습니다.
양방향 통신이 가능하지만, half-duplex 방식입니다.
→ 데이터를 한 번에 한 방향으로만 전송할 수 있으며, 양방향 통신을 하려면 두 개의 FIFO가 필요합니다.
같은 시스템 내에서만 동작합니다.
→ 네트워크를 통한 원격 시스템 간 통신은 지원되지 않습니다.
Windows에서의 Named Pipe
양방향 통신이 가능하며, full-duplex 방식입니다.
→ 데이터를 동시에 주고받을 수 있습니다.
같은 시스템뿐만 아니라 다른 시스템과도 통신할 수 있습니다.
→ 네트워크를 통해 다른 컴퓨터와도 Named Pipe를 사용할 수 있습니다.
CreateNamedPipe(), ConnectNamedPipe(), ReadFile(), WriteFile() 등의 API를 사용합니다.
→ 파이프를 생성하고, 연결을 설정한 후 데이터를 주고받을 수 있습니다.
명령어 예시
ls | more
→ ls 명령어의 출력을 more 명령어로 전달하는데, 이는 **파이프(|)**를 사용한 일반적인 프로세스 간 통신입니다.
dir | more
→ Windows에서 dir 명령어의 출력을 more 명령어로 넘기는 방식으로, UNIX의 ls | more와 동일한 개념입니다.
즉, Named Pipe는 UNIX와 Windows에서 각각 다르게 동작하지만, 공통적으로 프로세스 간 데이터를 주고받는 강력한 IPC(Inter-Process Communication) 도구입니다.
Unix Domain Socket (UDS)
로컬에서만 사용할 수 있는 IPC(Inter-Process Communication) 소켓 인터페이스입니다.
→ 네트워크 소켓과 비슷하지만, 같은 시스템 내에서만 작동합니다.
파일을 이용해 데이터를 주고받습니다.
→ Named Pipe(FIFO)처럼 파일 시스템 내에 소켓 파일을 생성하여 통신합니다.
네트워크 소켓과 유사하게 양방향(Bidirectional) 통신을 지원하며, 데이터 전송 방식은 스트림(Stream) 또는 데이터그램(Datagram) 방식이 가능합니다.
→ TCP 소켓처럼 연속적인 데이터 스트림 전송도 가능하고, UDP 소켓처럼 개별 메시지 단위로 보낼 수도 있습니다.
성능 비교:
Ordinary Pipe (일반 파이프) > Unix Domain Socket (UDS) > Named Pipe (FIFO) > Network Socket
→ 일반 파이프가 가장 빠르고, 네트워크 소켓이 가장 느립니다.
→ UDS는 Named Pipe보다 빠르고, 네트워크를 거치지 않기 때문에 일반 TCP/IP 소켓보다 성능이 좋습니다.
즉, Unix Domain Socket은 네트워크 소켓과 비슷한 방식으로 프로세스 간 통신을 지원하면서도, 같은 시스템 내에서 더 효율적인 성능을 제공합니다.
동기 (Motivation)
스레드는 애플리케이션 내부에서 실행됨
하나의 프로그램 안에서 여러 스레드가 동시에 실행될 수 있음.
애플리케이션 내의 여러 작업을 개별 스레드로 구현할 수 있음
예:
디스플레이 업데이트, 데이터 가져오기, 맞춤법 검사, 네트워크 요청 응답
프로세스 생성은 무겁지만, 스레드 생성은 가벼움
프로세스는 별도의 메모리 공간을 가지므로 생성과 관리에 더 많은 자원이 필요함.
반면 스레드는 메모리를 공유하기 때문에 더 빠르고 효율적으로 생성됨.
코드를 단순화하고 효율성을 높일 수 있음
여러 작업을 병렬로 처리하면서 코드 구조도 더 명확해질 수 있음.
커널도 일반적으로 다중 스레드로 동작함
운영체제 커널 자체도 여러 스레드를 이용해 다양한 작업을 동시에 처리함.
예시 (Examples)
웹 브라우저 (Web Browser)
스레드 1: 이미지를 화면에 표시
스레드 2: 텍스트를 화면에 표시
스레드 3: 네트워크로부터 데이터 가져오기
워드 프로세서 (Word Processor)
스레드 1: 그래픽 요소(문서 레이아웃 등) 표시
스레드 2: 키보드 입력에 반응
스레드 3: 맞춤법 및 문법 검사 수행
웹 서버 (Web Server)
각 클라이언트 요청을 처리하기 위해 프로세스 대신 스레드 사용
더 가볍고 빠르게 다수의 요청을 동시에 처리할 수 있음
커널 (Kernel)
운영체제 커널도 내부적으로 여러 스레드를 사용해 파일 시스템, 메모리 관리, 입출력 등 다양한 작업을 병렬로 처리함
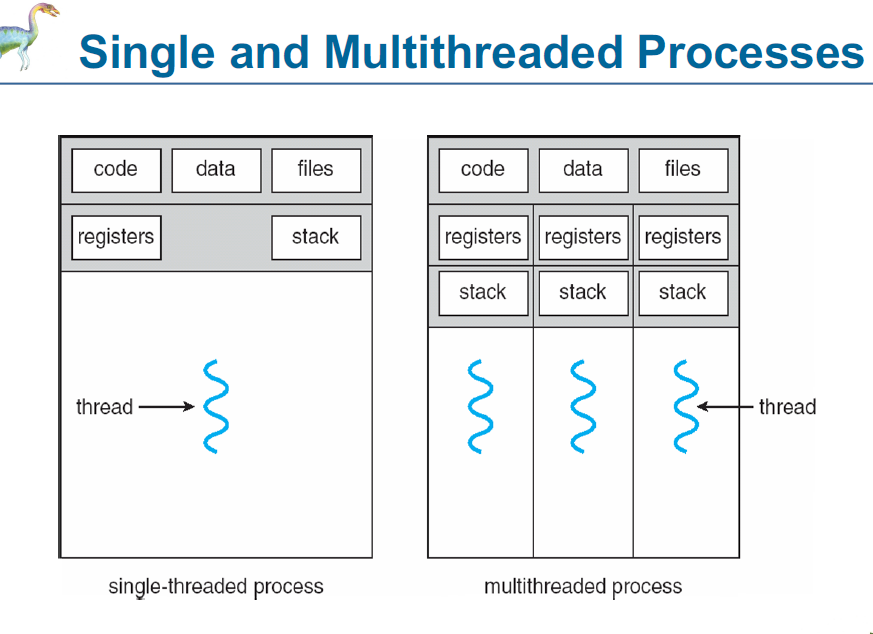
단일 스레드 프로세스와 다중 스레드 프로세스
왼쪽: 단일 스레드 프로세스
하나의 실행 흐름(thread)만 존재함.
코드, 데이터, 파일을 공유하지만, 하나의 레지스터(registers)와 스택(stack) 만 존재함.
프로세스 내부에서 하나의 작업만 수행 가능함.
오른쪽: 다중 스레드 프로세스
여러 개의 스레드가 존재함.
코드, 데이터, 파일을 공유하지만, 각 스레드는 개별적인 레지스터와 스택을 가짐.
여러 작업을 동시에 수행할 수 있어 성능 향상과 응답 속도 개선이 가능함.
이러한 구조 덕분에 멀티스레드 프로세스는 병렬 처리와 응답성 향상에 유리함
멀티스레드의 장점 (Benefits)
응답성 (Responsiveness)
일부 스레드가 작업을 수행하는 동안 다른 스레드가 사용자 입력을 처리할 수 있어 응답성이 향상됨.
예: 웹 브라우저에서 페이지 로딩 중에도 버튼 클릭이 가능함.
쉬운 자원 공유 (Easy Resource Sharing)
모든 스레드는 동일한 **주소 공간(Address Space)**을 공유함.
프로세스 간 통신(IPC)보다 더 간단하고 빠르게 데이터를 공유할 수 있음.
경제성 (Economy)
프로세스를 생성하는 것보다 스레드 생성 비용이 낮음.
문맥 전환(Context Switch) 비용도 프로세스보다 적게 소모됨.
확장성 (Scalability)
여러 개의 스레드를 다른 프로세서(Core)에서 병렬 실행할 수 있어 성능이 향상됨.
멀티코어 환경에서 효과적으로 활용 가능함.
멀티코어 프로그래밍 (Multicore Programming)
멀티코어 시스템이 보편화되면서, 프로그래머는 기존의 순차적 프로그래밍 방식에서 병렬 프로그래밍 방식으로 전환해야 합니다. 이를 구현하는 과정에서 다음과 같은 **도전 과제(Challenges)**가 발생함
작업 분할 (Dividing Activities)
프로그램을 여러 개의 병렬 실행 가능한 작업으로 나누는 것이 필요함.
단순히 여러 개의 스레드를 만든다고 해서 성능이 자동으로 향상되지 않음.
부하 균형 (Balance)
각 코어에 작업이 균등하게 배분되어야 성능을 최적화할 수 있음.
특정 코어에 작업이 집중되면 다른 코어가 유휴 상태(idle)가 되어 성능이 저하될 수 있음.
데이터 분할 (Data Splitting)
각 스레드가 처리할 데이터를 적절히 나누는 것이 중요함.
동일한 데이터에 여러 스레드가 동시에 접근하면 **경쟁 상태(Race Condition)**가 발생할 수 있음.
데이터 의존성 (Data Dependency)
하나의 작업이 다른 작업의 결과를 필요로 할 경우, 병렬 실행이 어려워짐.
이를 해결하려면 동기화(Synchronization) 기법을 적절히 활용해야 함.
테스트 및 디버깅 (Testing and Debugging)
병렬 프로그램은 실행 순서가 매번 다를 수 있어 디버깅이 매우 어려움.
데드락(Deadlock), 경쟁 상태(Race Condition) 등의 문제를 찾고 수정하는 것이 도전 과제가 됨.
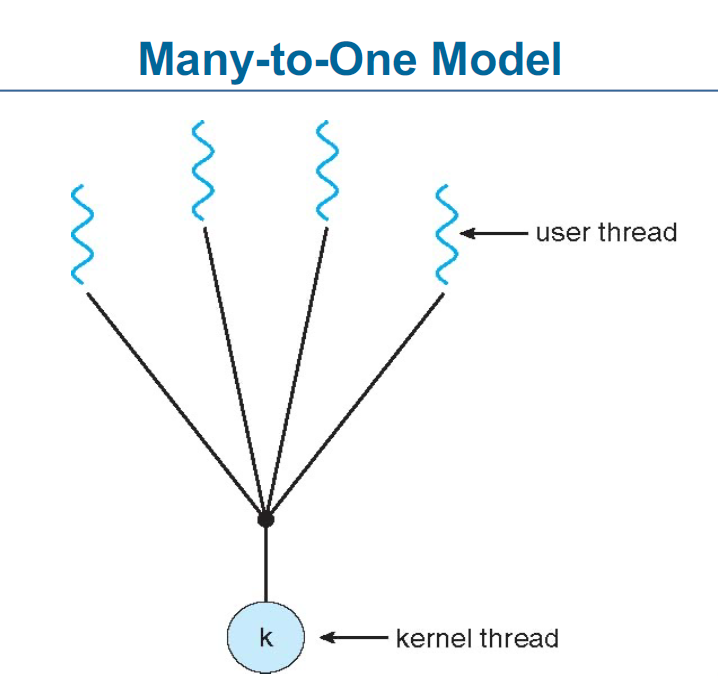
Many-to-One 멀티스레딩 모델
여러 개의 **사용자 스레드(User-Level Thread)**가 하나의 **커널 스레드(Kernel Thread)**에 매핑됨.
운영체제는 사용자 스레드를 직접 관리하지 않고, 커널 스레드가 사용자 스레드를 대신 실행함
예제 시스템:
Solaris Green Threads
GNU Portable Threads
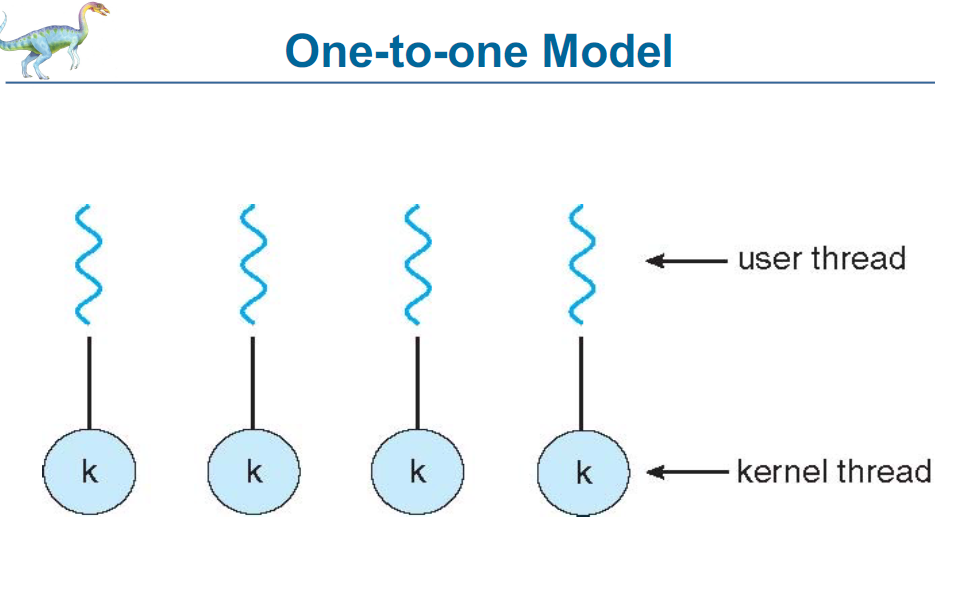
One-to-One 멀티스레딩 모델
각각의 **사용자 수준 스레드(User-Level Thread)**가 하나의 **커널 수준 스레드(Kernel Thread)**에 1:1로 매핑됨.
운영체제가 스레드를 직접 관리하며, 각 스레드는 별도의 커널 스레드로 동작함.
특징:
✅ 장점:
진정한 병렬 처리 가능
여러 스레드가 동시에 멀티코어 CPU에서 병렬로 실행될 수 있음.
하나의 스레드가 **블로킹(blocking)**되더라도, 다른 스레드는 계속 실행 가능.
운영체제가 직접 스케줄링을 관리하므로 성능이 우수함.
❌ 단점:
스레드마다 커널 자원을 사용하므로 스레드 수가 많아지면 시스템 자원 고갈 가능성.
스레드 생성, 종료, 전환(context switch) 등의 비용이 상대적으로 큼.
예제 시스템:
Windows NT/2000/XP
Linux
Solaris 9 이후 버전
>>>>>>>>>>>>>>>>>>>
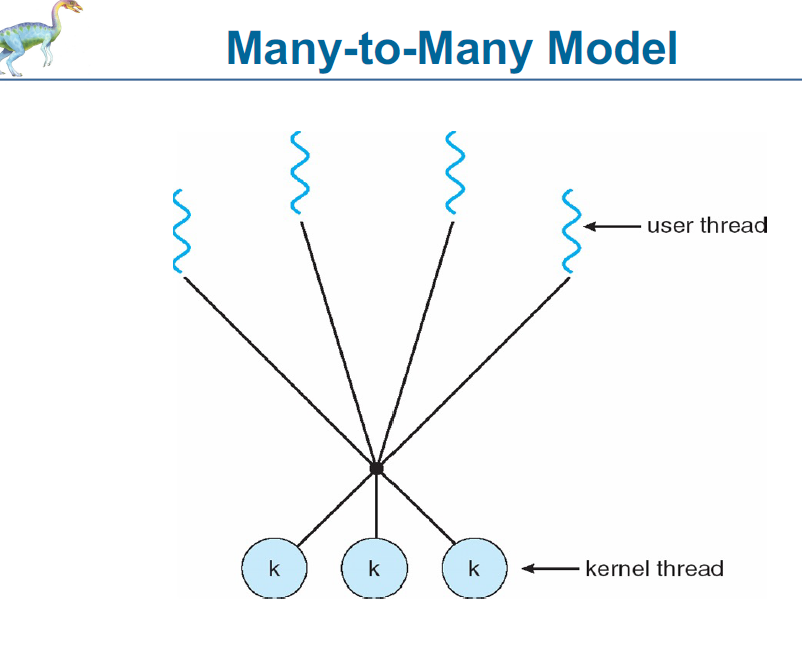
Many-to-Many 멀티스레딩 모델
여러 **사용자 수준 스레드(User-Level Threads)**가 여러 **커널 수준 스레드(Kernel Threads)**에 **다대다(Many-to-Many)**로 매핑됨.
사용자 스레드 수와 커널 스레드 수가 1:1로 고정되지 않으며, 유동적으로 매핑됨.
특징:
✅ 장점:
운영체제가 필요한 만큼 커널 스레드를 생성해서 효율적으로 스케줄링할 수 있음.
블로킹 문제 해결 가능: 어떤 사용자 스레드가 블로킹되더라도 다른 스레드는 계속 실행될 수 있음.
병렬 실행 가능: 여러 커널 스레드를 통해 멀티코어 활용 가능.
자원 효율성 + 병렬성을 모두 추구하는 모델.
❌ 단점:
구현이 복잡하고, 운영체제의 지원이 필요함.
사용자 스레드를 어떻게 커널 스레드에 매핑할지 결정하는 **런타임 시스템(runtime system)**이 필요함.
예제 시스템:
Solaris 8 및 그 이전 버전
Windows NT/2000 + ThreadFiber 패키지
>>>>>>>>>>>>
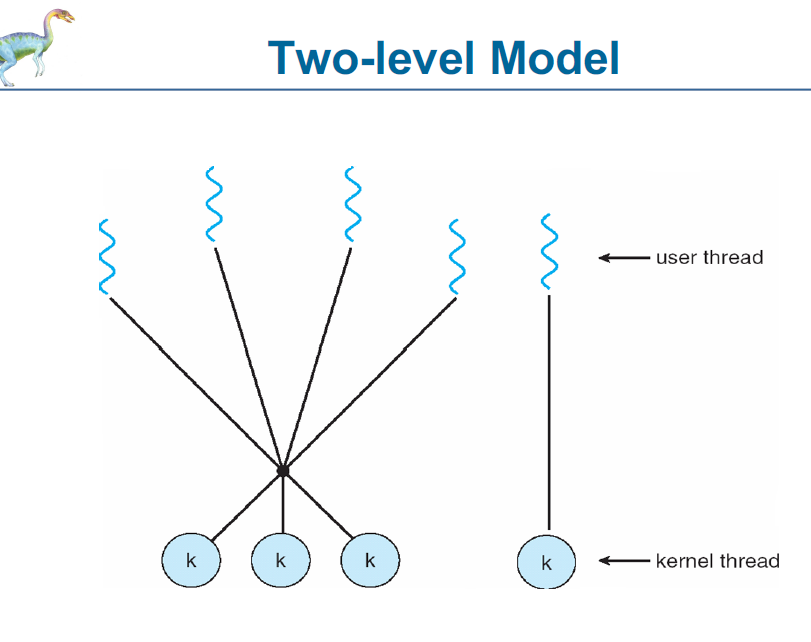
Two-Level Model (이중 레벨 모델)
Many-to-Many(M:M) 모델과 유사하지만, **특정 사용자 스레드를 특정 커널 스레드에 고정(binding)**할 수 있는 기능이 추가됨.
즉, 대부분의 사용자 스레드는 커널 스레드와 유동적으로 매핑되지만, 중요한 스레드는 커널 스레드와 1:1로 연결할 수 있음.
특징:
✅ 장점:
유연성: 필요할 때마다 다대다 방식으로 동작하고, 특정 경우에는 일대일 방식으로 고정 가능.
성능 향상: 중요하거나 실시간 처리가 필요한 스레드는 직접 커널 스레드에 매핑하여 성능 확보 가능.
블로킹 해결 + 병렬 처리 가능: 다대다의 장점 유지하면서 일부 일대일 방식으로 안정성 향상.
❌ 단점:
구현이 복잡하고, 사용자와 시스템 모두 스레드 관리에 신경을 써야 함.
운영체제 차원에서 별도의 스레드 관리 정책이 필요함.
예제 시스템:
IRIX
HP-UX
Tru64 UNIX
Solaris 8 및 이전 버전
>>>>>>>>>>>>>
Thread Libraries (스레드 라이브러리)
정의:
스레드 라이브러리는 프로그래머가 스레드를 생성하고 관리할 수 있도록 API를 제공하는 소프트웨어 도구입니다.
스레드의 생성, 종료, 동기화 등을 쉽게 구현할 수 있게 도와줍니다.
스레드 라이브러리 구현 방식 (2가지)
1. 완전히 사용자 공간(User Space)에 구현된 라이브러리
운영체제 커널의 개입 없이, 라이브러리 수준에서 스레드를 관리함
2. 운영체제가 지원하는 커널 수준(Kernel Level) 라이브러리
스레드를 커널이 직접 관리함.
대표적인 스레드 라이브러리 (3가지)
POSIX Pthreads (Portable Operating System Interface for Unix Threads)
커널 수준 구현 가능
Win32 Threads
커널 수준에서 관리됨.
Java Threads
JVM이 호스트 운영체제에 따라 적절히 스레드를 매핑함
>>>>>>>>>>>>>>>>
Java 스레드
Java 스레드는 JVM(Java Virtual Machine)에 의해 관리된다.
JVM은 호스트 머신의 스레드 모델을 기반으로 작동한다.
Java는 스레드를 위한 풍부한 지원을 제공한다.
모든 Java 프로그램은 JVM 내에서 하나의 스레드로 실행된다.
Java 스레드는 다음 두 가지 방법으로 생성할 수 있다:
Thread 클래스 사용
Thread 클래스를 상속한다.
run() 함수를 구현한다.
Runnable 인터페이스 사용
Runnable 인터페이스를 구현한다.
'운영체제' 카테고리의 다른 글
| fork, IPC (0) | 2025.03.30 |
|---|---|
| Processes, Scheduling, fork() (0) | 2025.03.24 |
| 메모리, 마이크로커널 / 모놀리식 시스템 구조, 프로세스 (0) | 2025.03.17 |
| Computer Organization 컴퓨터 구성/구조 (0) | 2025.03.08 |